自社のデータが利益を生む!機械学習のプロジェクトマネジメントとは?

ビッグデータ分析や機械学習が盛り上がる中、自社でも機械学習のプロジェクトを立ち上げようとしている企業も多いのではないでしょうか。しかし、機械学習に精通した人材がおらず、何から始めていいかわからないという声も多く聞きます。
自社にデータが蓄積されていても、それを機械学習のツールに投入するだけでは生産性向上や業務効率化といった成果につながりません。成果につなげるためには、データ分析や機械学習とは何かを理解したうえで、機械学習のPDCAサイクルを適切に回していく必要があります。
本記事ではサーキュレーションで行われた、データ分析・AI技術を用いた生産性向上・サービス開発のプロによるセミナーの内容をもとに、機械学習のプロジェクトマネジメントのポイントを解説します。

セミナー登壇者様:木村隆介氏
日立製作所→リクルートライフスタイル データマネジメントグループ。
データ分析・AI技術を用いた生産性向上・サービス開発のスペシャリスト。日立製作所では自社&他社工場向けに、ビッグデータ分析による生産管理や歩留まりに貢献。リクルートライフスタイル データマネジメントグループではBIツール構築による営業生産性向上や、AI技術を用いた宿泊施設向けサービスを開発。
Contents
データ分析/機械学習とは何か
そもそもデータ分析や機械学習とは何でしょうか。機械学習のプロジェクトマネジメントを成功させるためには、まずデータ分析や機械学習とは何かを押さえておく必要があります。
ビジネスにおけるデータ分析/機械学習の意義
ビジネスにおいて有効なデータとは何でしょうか。情報とは何が違うのでしょうか。
その違いは、ビジネスで直面している課題の解決や意思決定に役立つか否かにあります。意思決定することができない数字の羅列は、ただのデータです。意思決定ができるものが情報なのです。言うまでもなくビジネスにおいては、意思決定やその後の行動につながるデータ分析でなければ意味がありません。
つまり、データ分析とはデータを加工し情報にすることなのです。
なぜデータ分析/機械学習の基礎を身につけるとよいのか
そもそも問題解決の手法は、世の中に2つしかありません。それは、演繹法と帰納法です。演繹法とは一般論を特定事象に当てはめて結論を導き出す方法であり、帰納法とは観察事象から共通点を見つけ出して結論を導き出す方法です。
データ分析や機械学習が関わるのは帰納法です。例えば下記のような事例の場合、もし治験者が3人であり、そのうち1人だけが治った場合はどうなるでしょうか。
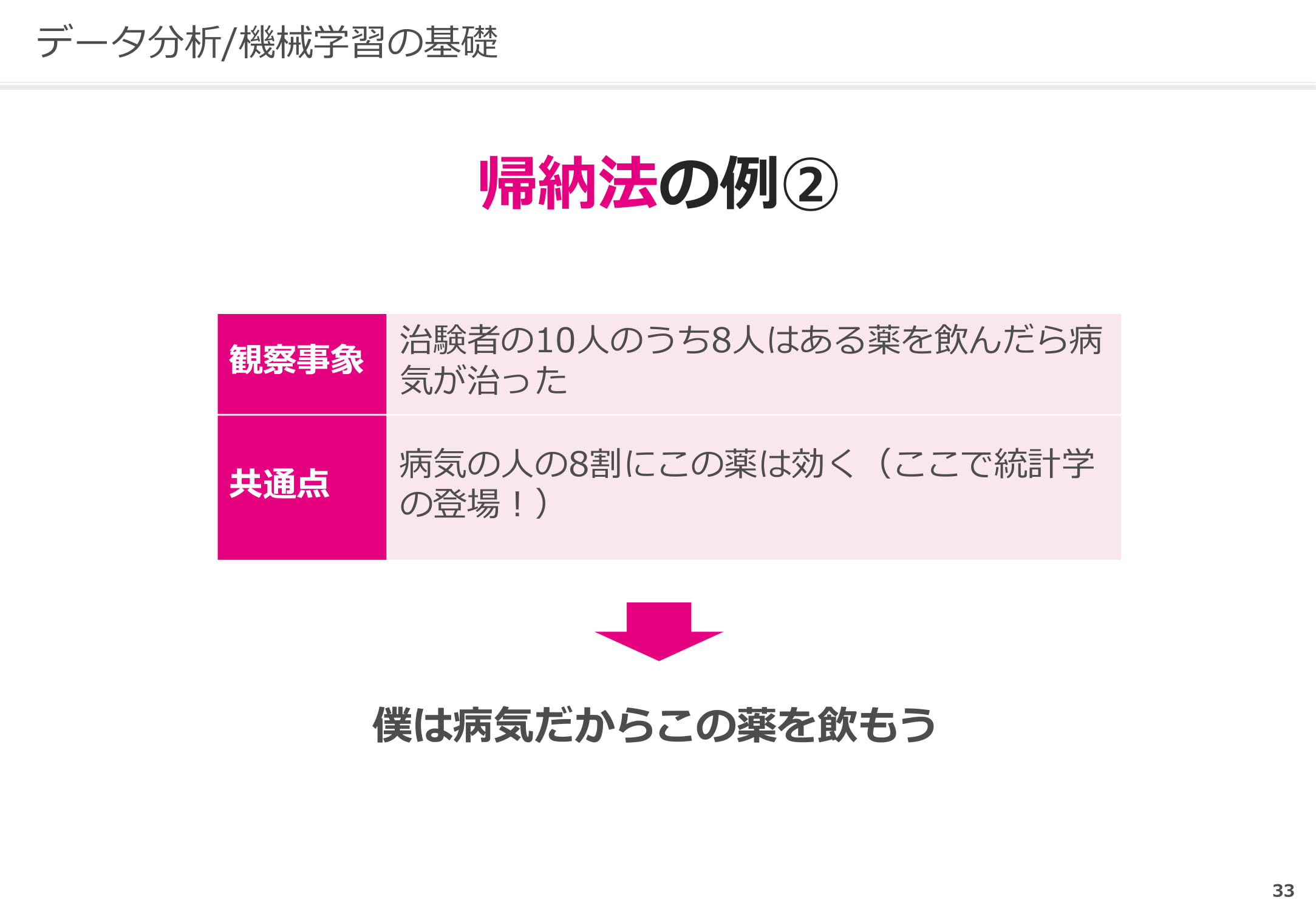
データ分析ができれば、データ数が適切かどうか判断できます。
すなわちデータ分析ができないということは、2つしかない問題解決の手法のうち1つを失うことになるのです。もちろん高度で専門的なことを身につける必要はありません。基本的な考え方を理解しておけば十分です。
機械学習はどのように行うのか
それでは、実際にデータ分析/機械学習はどのように行うのか、具体例をもとに見ていきましょう。
データ分析/機械学習の事例
下の写真は3種類のアヤメです。似ているように見えますが、よく見るとPetal(花弁)やSepal(萼)などに違いがあります。例えば、Iris Versicolorの場合Sepalの幅が他より広くなっています。
データで見ると、下記の表のようになります。Sepalがどの長さの時に、どの種類のアヤメであるかなどがわかります。

ここからSepalとPetalの長さと幅を縦軸と横軸にとって分類すると、品種が色別にきれいに分類されるのがわかります。
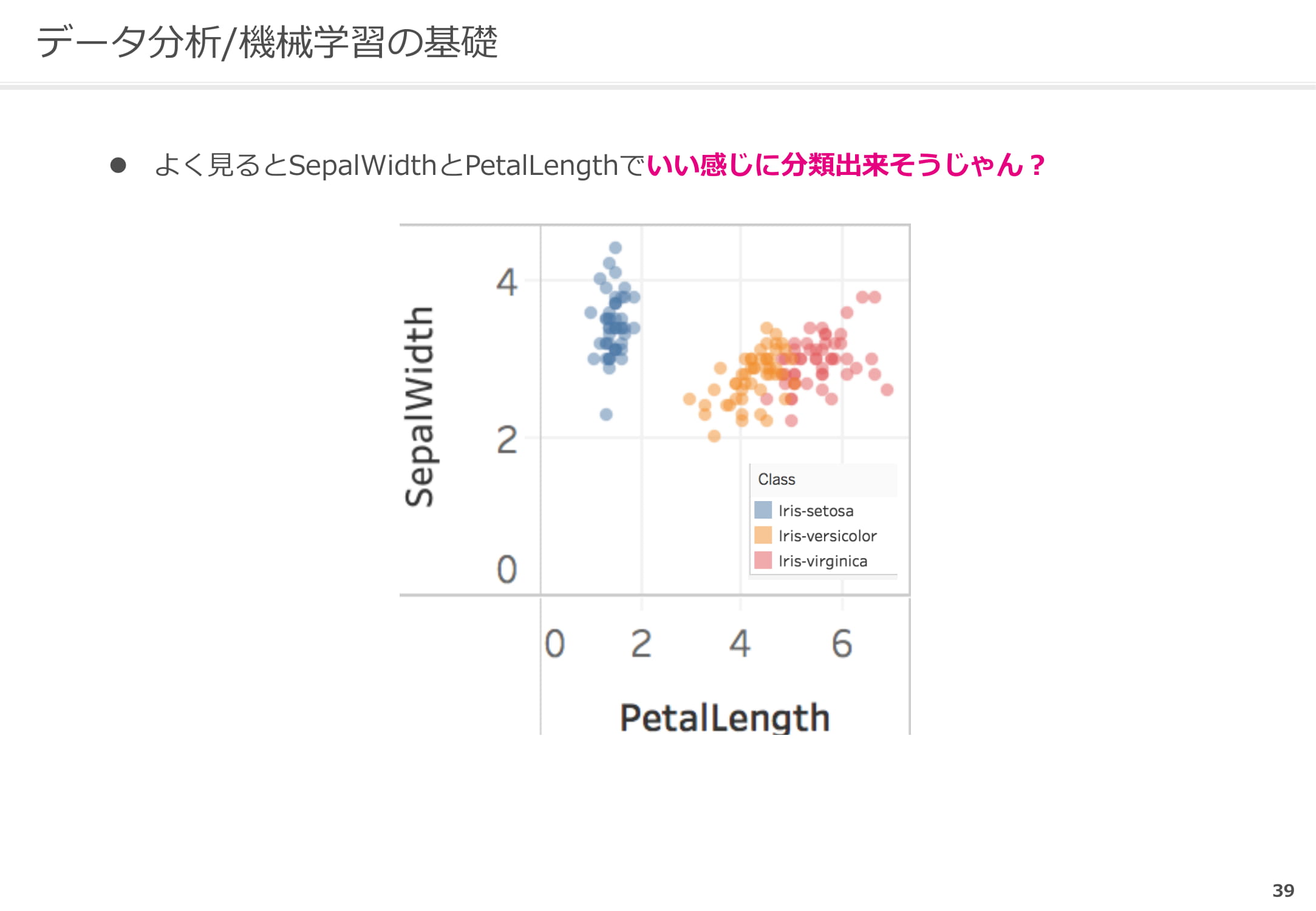
このような分析は、ビジネスにどのように応用できるでしょうか。例えば製造業で、縦軸と横軸を圧力などで分類します。もし、青が不良品でオレンジが良品になれば、どの条件で製造すれば不良品を出さないですむかがわかります。
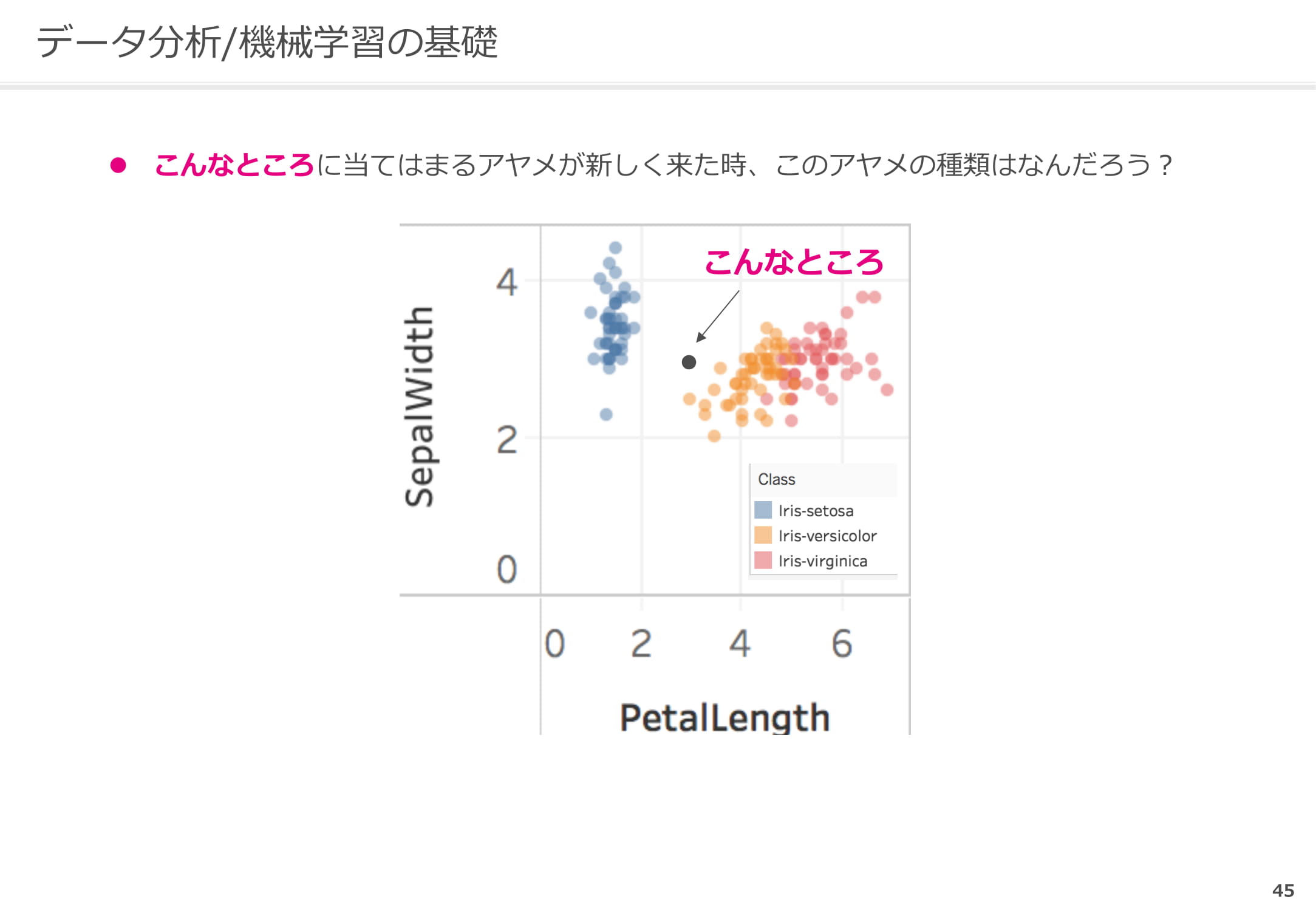
ここまででデータ分析は終わりです。工場の事例のように、この時点で有益な情報が得られていればよいですが、そうでない場合に機械学習の手法が役立つのです。例えば下記のグラフのように新しい場所にプロットされた場合、アヤメの種類は何になるでしょうか。工場の場合、不良品か良品かをどのように判断すればいいでしょうか。
ここからが、機械学習の領域になります。
機械学習の考え方
機械学習の考え方は次の2つです。
-
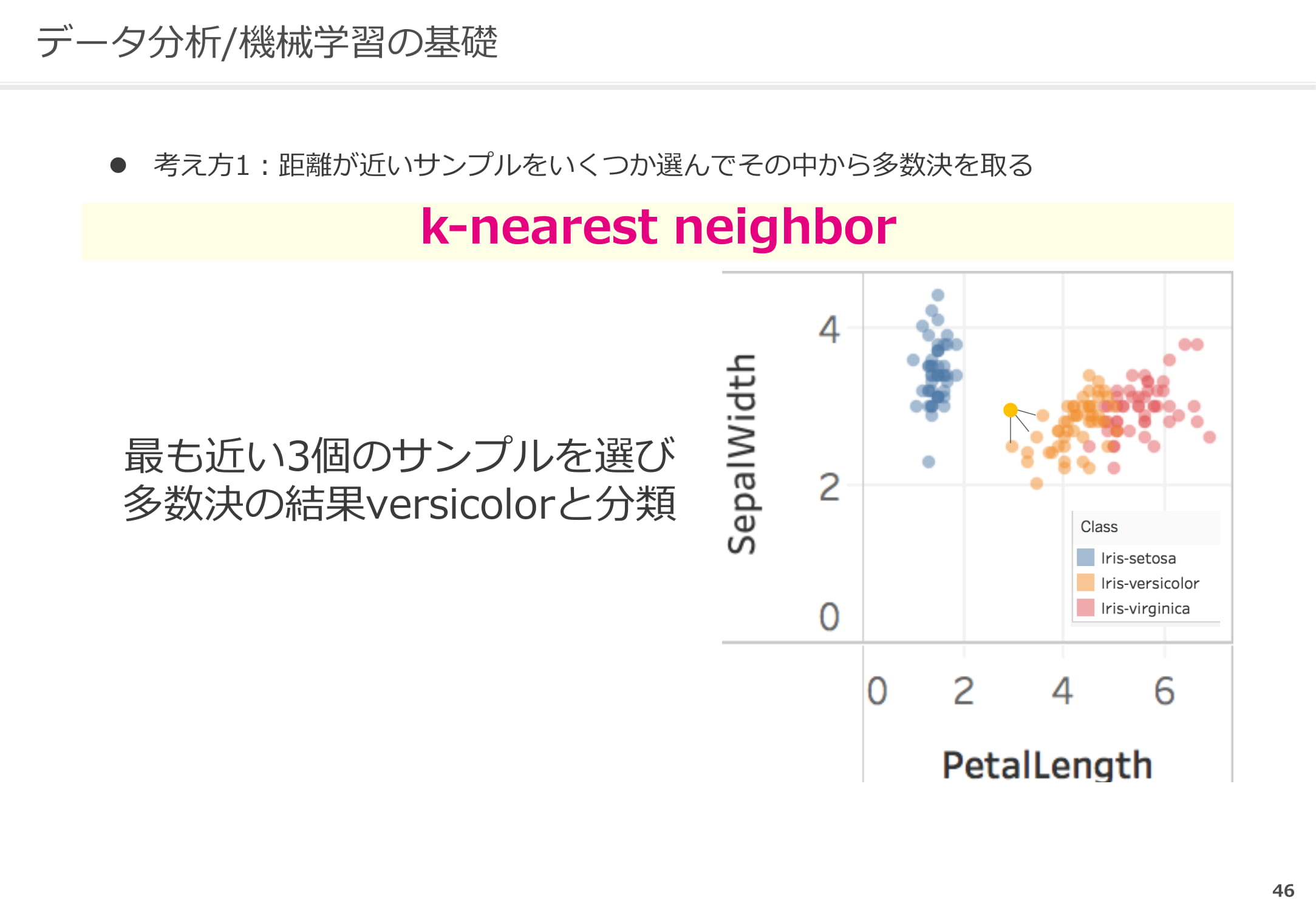
距離が近いサンプルを選んで多数決を採る方法
最も近い3個のサンプルを選び、多数決を取るというものです。そうすることで、新しくプロットされたものを分類することができます。これは機械学習の最もシンプルな考え方です。
-
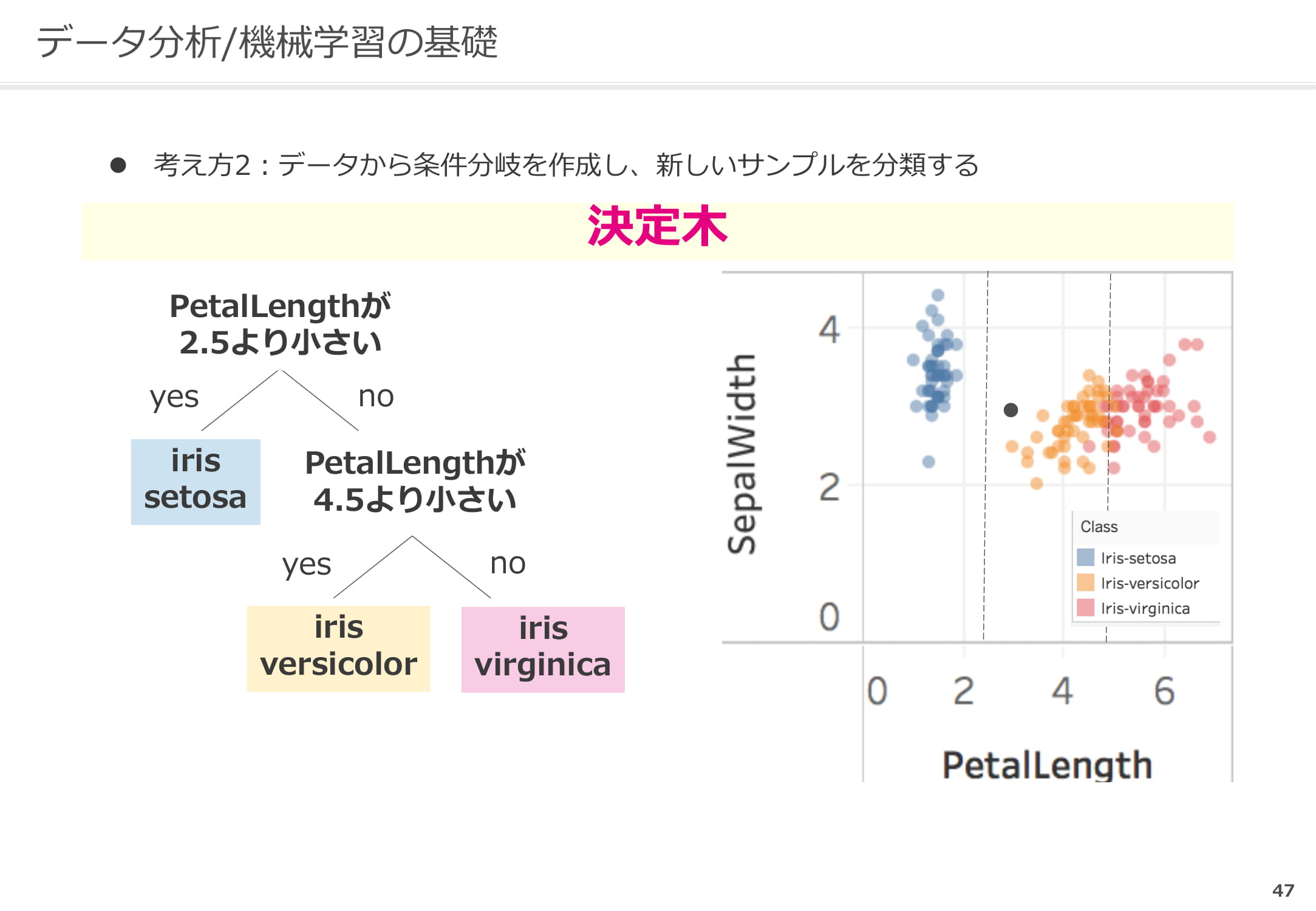
データから条件分岐を作成し、新しいサンプルを分類する方法
決定木と呼ばれるもので、データから条件を作成し分岐させていきます。例えば下記のように長さの条件を作成します。分岐をしていくと、新しいサンプルがいずれかに分類されます。
機械学習は難しいと思われている方も多いと思いますが、考え方はこのように非常にシンプルです。
機械学習を用いたプロジェクトマネジメントとは
それでは実際に、機械学習を用いたプロジェクトマネジメントを進めていく場合、どんな手順で進めたらよいのでしょうか。
ここからは、機械学習を用いたプロジェクトマネジメントの具体的なポイントを見ていきましょう。
フレームワークを活用する
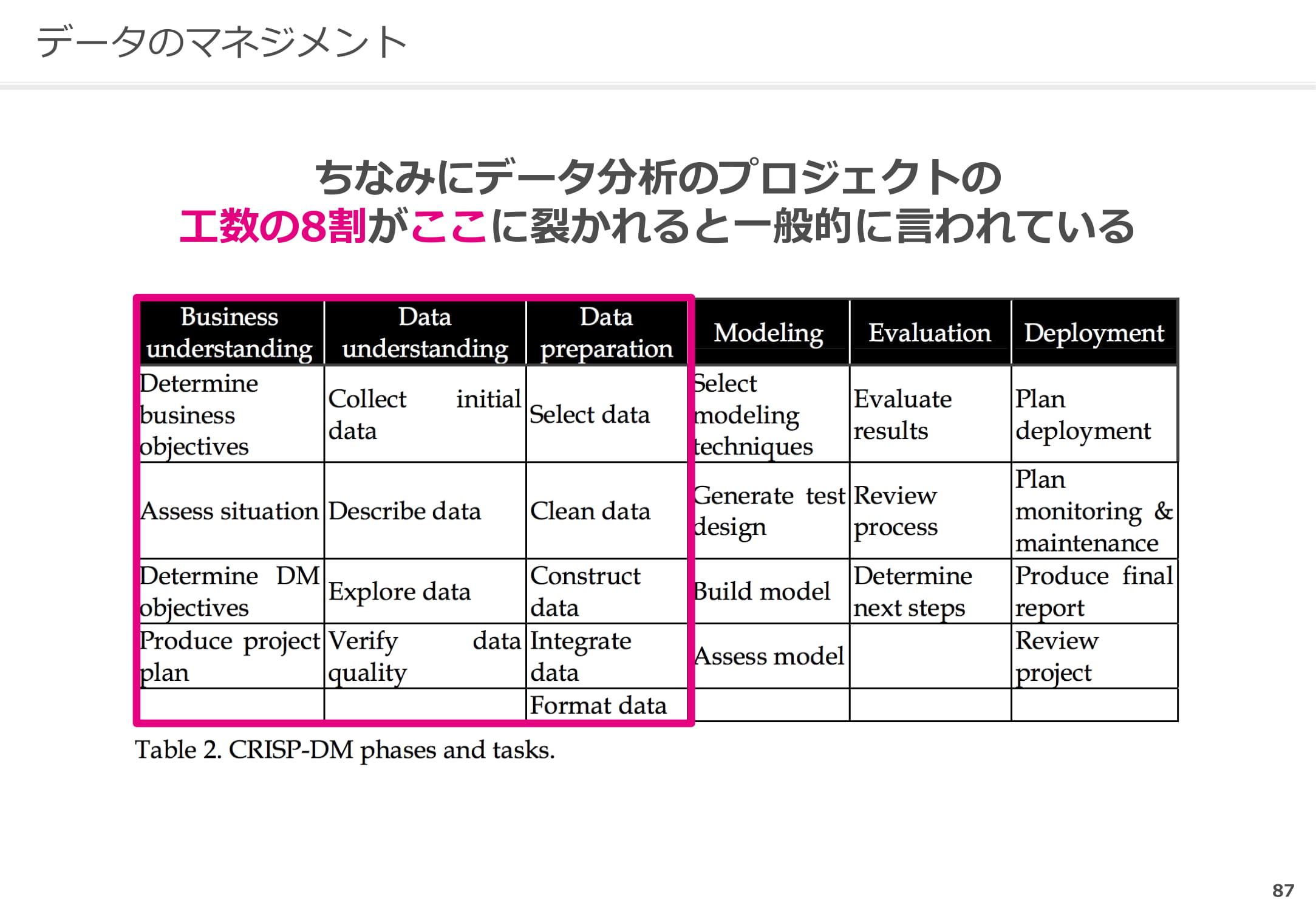
機械学習を用いたプロジェクトマネジメントでは、既存のフレームワークの活用が効果的です。最も利用されているフレームワークがCRISP-DMです。
CRISP-DMは6つのPhaseから構成されており、各Phaseは複数の『Generic Task』から構成されています。
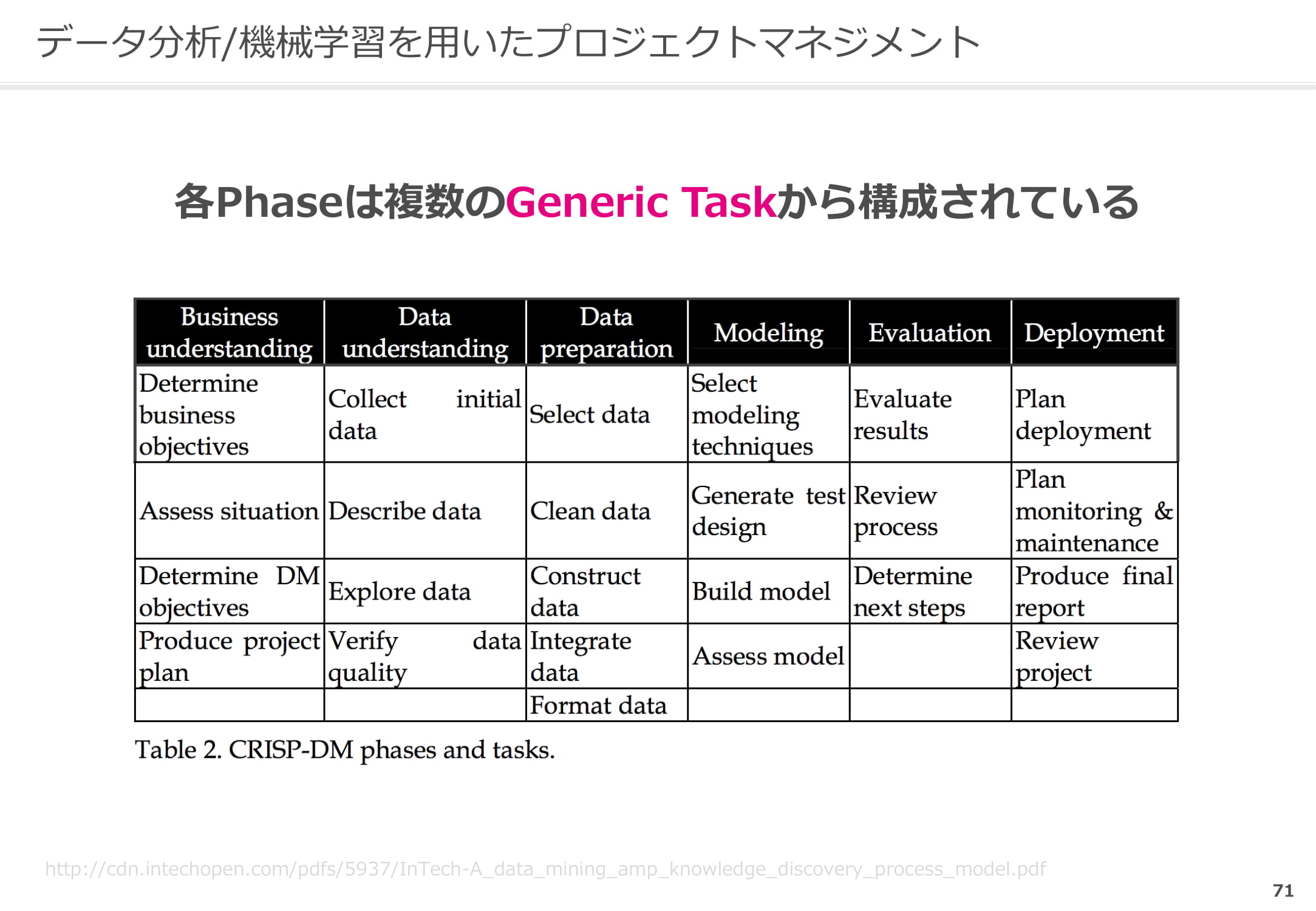
データを目の前にするといきなり分析しがちですが、6つのフェーズを押さえることが重要です。CRISP-DMでは、まず『Business understanding』、つまりビジネス課題の理解から始めます。その後、使えるデータの特定や細かい部分までひとつひとつ理解し、データを選別したり統合したりします。そしてようやく『Modeling』、つまり具体的に機械学習を試すフェーズに入ります。その結果を受けて検証し、結果が出なかったらまた『Business understanding』に戻るという形で進めていくのが王道です。
CRISP-DMは業界横断で使えるフレームワークですので、まずはこれに沿って進めていくことをお薦めします。
データマネジメントの重要性
先ほども述べたように、機械学習のプロジェクトマネジメントではビジネスを理解したうえでデータを準備する必要があります。ちなみに、プロジェクト工数の8割が『Business understanding』から『Data preparation』までに割かれていると言われています。
したがってこの工数を削減するデータマネジメントが重要になるのです。
その際、データ基盤の作り方もポイントになります。データには社内データと社外データがあります。社内データには会計や人事、口コミなどの膨大なデータがあり、社外データには位置情報や気象情報などの様々なデータがあります。これらのデータをただ蓄積するのではなく、分析する際によく結合するものはあらかじめ結合しておくなどの工夫をすることでデータ活用が効果的になります。
まとめ:機械学習のプロジェクトマネジメント成功のために
これまで見てきたように、やみくもにデータを蓄積したり分析したりしていても、生産性向上や業務効率化にはつながりません。データ分析/機械学習の考え方を理解したうえで、PDCAサイクルを回していくことが重要です。
機械学習のプロジェクトマネジメントに取り組んでみようとお考えの企業の方は、本記事を参考にまずはCRISP-DMに沿って実践してみてはいかがでしょうか。
なお、本記事はセミナーでお話しいただいた内容から一部を抜粋したものです。セミナーでは、ほかにも機械学習のプロジェクトマネジメントの取り組み事例などたくさんのトピックスについてお話しいただきました。もっと詳しく聞きたい方は、次回の開催をご期待ください。
60の新規事業を推進した開発PMが語る ―停滞する新規事業立ち上げを推進する3つのポイント―